
Le mois de mai 2026 a apporté d'importantes nouveautés dans l'écosystème,
Snowflake finalise sa vision du Data Lakehouse ouvert en passant l'écriture sur les tables Iceberg par des moteurs externes en "General Availability". Côté ingénierie, l'intégration de dbt franchit un nouveau cap avec le lignage à la colonne, et les développeurs IA bénéficient enfin d'un studio dédié pour optimiser leurs modèles. Nous allons voir les 4 actualités majeures de Snowflake.
1/ Mise à jour majeure pour dbt sur Snowflake
Pour les équipes utilisant l'intégration native dbt Projects dans Snowflake, la mise à jour du mois de mai est sans doute la plus importante de l'année. Snowflake ne se contente plus d'héberger dbt, mais améliore les performances et l'ergonomie. Voici tout ce qui change :
Performances & gestion des versions
- Nouveau Moteur "dbt Fusion" : Snowflake intègre Fusion, une réécriture complète du moteur d'exécution dbt en langage Rust. Il implique des temps de compilation drastiquement réduits pour les très gros projets. Ce moteur est inclus d'office, sans surcoût de licence.
- Support Multi-versions : Vous pouvez désormais "épingler" une version spécifique de dbt à la création de votre projet via le paramètre DBT_VERSION (ex: Core 1.9.4, 1.10.15 ou Fusion 2.0)
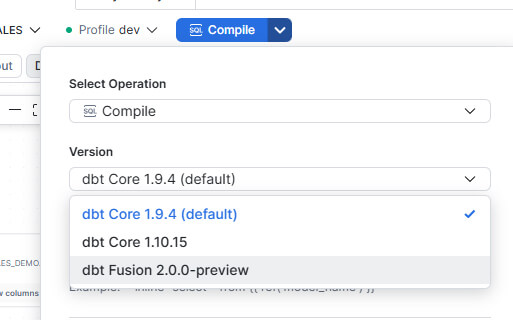
Exemple des versions disponibles au 1 Juin 2026
Analyse d'impact (Graphe DAG) & Exécution ciblée
- Lignage à la colonne : Le graphe de dépendances (DAG) affiche désormais les colonnes de chaque modèle. Cliquez sur une colonne, et Snowflake met en surbrillance tout son cheminement en amont et en aval
- Exécution partielle depuis le DAG : Directement depuis l'interface visuelle du DAG, un clic droit sur un nœud permet de lancer uniquement ce modèle, ses parents, ou ses enfants, sans relancer tout le projet
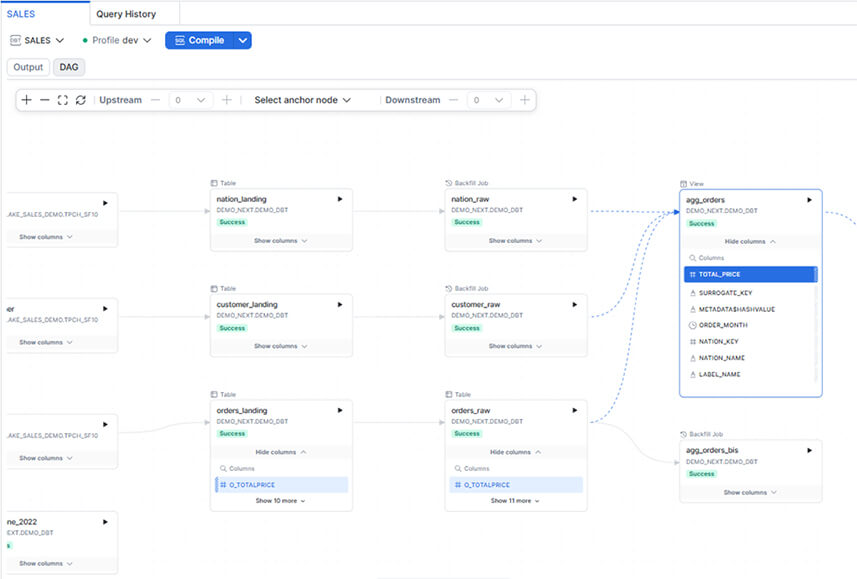
Exemple de lignage à la colonne
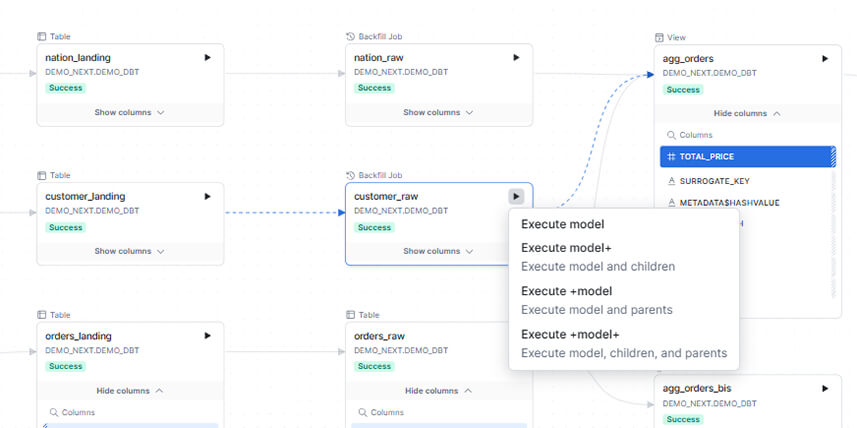
Exemple d'exécution partielle depuis le DAG
Productivité augmentée (Workspaces & IA)
- Cortex Code pour dbt : L'assistant IA de Snowflake s'invite dans dbt. Vous pouvez lui demander de générer la structure d'un modèle, d'ajouter des tests, ou de rédiger la documentation automatiquement
- Exécution unitaire : Dans l'éditeur Workspaces, un nouveau bouton "Run" permet d'exécuter ou compiler un seul fichier de modèle isolé
- Import de projets : Vous pouvez importer le contenu d'un projet dbt déjà déployé directement dans un Workspace pour l'éditer et itérer dessus facilement
- Logs ajustables : La fonction d'audit SYSTEM$GET_DBT_LOG accepte désormais un paramètre permettant de choisir le nombre de lignes à récupérer (par défaut 1 000, jusqu'à 10 Mo de logs)
Cortex AI Function Studio (Public Preview)
Passer d'un simple test de "prompt" à une fonction IA robuste et déployable en production est souvent complexe. Pour résoudre ce problème, Snowflake lance la création de fonction custom dans le Cortex AI Function Studio (en Public Preview). Ce nouvel outil automatise l'ingénierie des prompts, la sélection des modèles et l'évaluation continue pour vos flux de données non structurées et multimodales.
Les capacités clés :
- Création en langage naturel : Vous pouvez générer des fonctions IA simplement en décrivant la tâche souhaitée en langage naturel, que ce soit via l'interface graphique (Snowsight AI Studio) pour les Data Analysts, ou en ligne de commande (Cortex Code CLI) pour les AI Engineers
- Optimisation automatisée (Task-specific) : Fini l'approche "un modèle générique pour tout faire". Le Studio automatise le benchmarking et l'optimisation des prompts et de la sélection du modèle pour garantir la meilleure qualité possible en fonction de votre tâche spécifique et de vos données
- Support Multimodal complet : Les fonctions que vous créez peuvent traiter une grande variété de formats : textes classiques, mais aussi documents, images, et désormais l'audio et la vidéo (selon les capacités du modèle sous-jacent)
- Évaluation intégrée : Le studio intègre directement des métriques d'évaluation configurables pour tester rigoureusement vos stratégies avant tout déploiement en production.
En Preview : l’écran de création de nouvelles fonctions IA
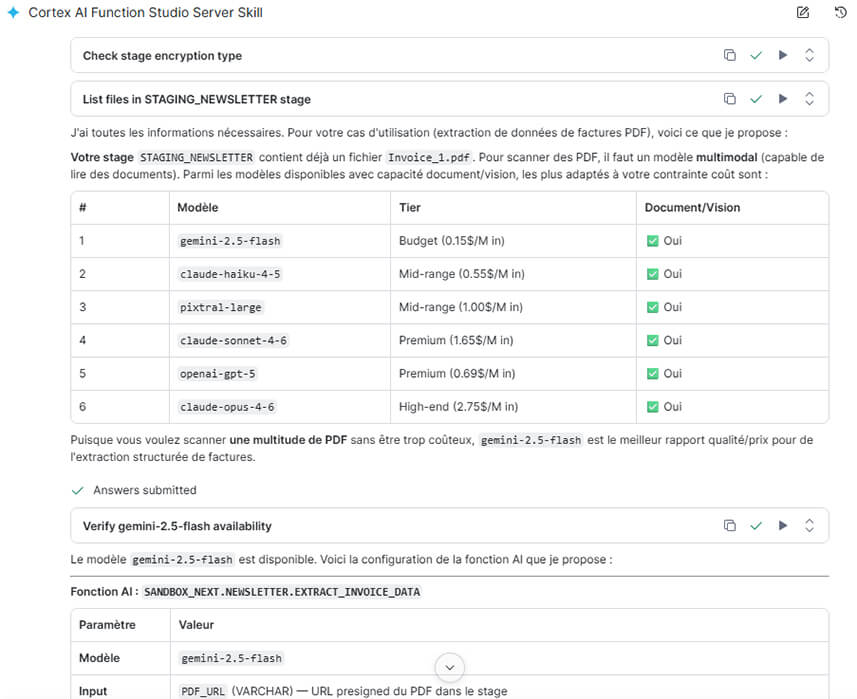
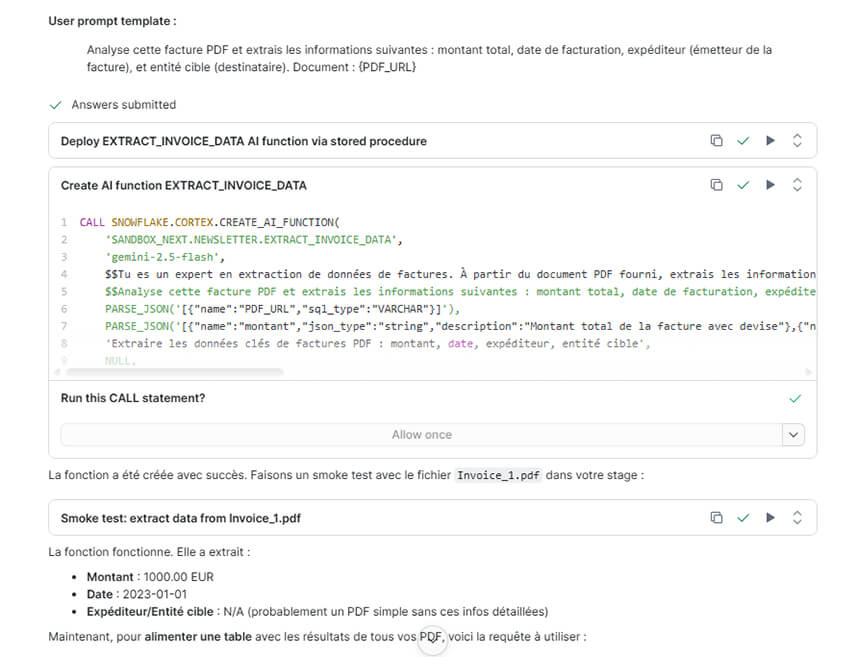
Exemple de processus de création de fonction IA Custom, avec choix du modèle et comparatif de coût
Connecteur SAP BDC "Zero-Copy" (General Availability)
Annoncée plus tôt cette année, l'intégration stratégique entre SAP et Snowflake franchit une étape décisive en passant en "General Availability". Le SAP BDC Zerocopy Connector est désormais prêt pour la production. Il permet de partager des données de manière bidirectionnelle entre votre écosystème SAP et Snowflake, sans aucune duplication physique ni pipeline ETL.
Êtes-vous concerné par cette nouveauté ?
Ce connecteur s'adresse à toute entreprise utilisant SAP Business Data Cloud (BDC). Pour couvrir tous les cas de figure, Snowflake et SAP ont prévu deux périmètres d'intégration distincts :
- Vous possédez déjà un compte Snowflake : C'est le parcours "SAP BDC Connect". Via un simple lien d'invitation généré depuis votre portail SAP for Me, vous connectez votre instance Snowflake existante à votre environnement SAP.
- Vous n'avez pas encore de compte Snowflake : C'est le parcours "SAP Snowflake". Vous pouvez provisionner un nouveau compte Snowflake (incluant le connecteur) directement depuis votre portail d'administration SAP, de manière totalement intégrée
Le gain concret pour votre architecture : Une fois la connexion établie, les "Data Products" de votre ERP SAP apparaissent directement dans Snowflake sous forme de bases de données liées. Vous pouvez alors :
- Requêter vos données financières ou logistiques en temps réel via SQL
- Croiser vos données SAP avec le reste des données de votre entreprise déjà présentes dans Snowflake
- Utiliser les vues sémantiques SAP pour alimenter nativement les outils d'Intelligence Artificielle de Snowflake (comme Cortex Analyst), tout en renvoyant si besoin le résultat de vos analyses vers SAP
L'écosystème Apache Iceberg finalisé (General Availability)
L'écriture ouverte par des moteurs tiers, l'authentification OIDC et le support de la v3
Depuis des années, Snowflake milite pour séparer le calcul du stockage. Avec les annonces de ce mois de mai (en GA depuis le 7 et le 26 mai), la promesse est intégralement tenue : vous n'êtes plus contraints d'utiliser le moteur de calcul Snowflake pour modifier vos tables gérées par Snowflake.
Les avancées majeures pour votre architecture :
- Écriture externe (Write Support) : C'est la révolution de cette release. Vous pouvez désormais utiliser des moteurs de calcul externes (comme Apache Spark™) pour lire ET écrire dans des tables Iceberg gérées par Snowflake
- Sécurité centralisée & Authentification WIF (Nouveau) : Votre moteur Spark s'authentifie via le Snowflake Horizon Catalog en utilisant le standard Iceberg REST. Surtout, cette release introduit le support du Workload Identity Federation (WIF) basé sur OpenID Connect (OIDC). Vos clusters externes s'authentifient désormais de manière ultra-sécurisée via des tokens, tout en respectant vos politiques de rôles (RBAC) Snowflake
- Support officiel d'Apache Iceberg v3 : Le format v3 apporte des optimisations de performance cruciales (types de données avancés et deletion vectors), accélérant drastiquement les opérations UPDATE et DELETE sur les gros volumes en évitant de réécrire des fichiers entiers.
L'impact pour votre business :
Si vous possédez de lourds pipelines d'ingestion Spark existants, ne les réécrivez pas. Laissez Spark faire le travail d'écriture "brute" directement dans les tables gérées par Snowflake de manière sécurisée (OIDC), et utilisez le moteur Snowflake pour la BI, l'analytique et l'IA avec une gouvernance unifiée.
En Bref : Les autres nouveautés de Snowflake Mai 2026
L'Intelligence Artificielle en continu
- Arrivée de Gemini 3.5 Flash : La fonction AI_COMPLETE intègre désormais le modèle ultra-rapide Gemini 3.5 Flash, optimisant l'analyse multimodale (notamment vidéo et audio) avec un rapport vitesse/prix imbattable
- Baisse de prix massive sur AI_TRANSCRIBE : Snowflake annonce une réduction tarifaire allant jusqu'à 60% pour la transcription audio et vidéo
- Scores de confiance (GA) : La fonction AI_EXTRACT renvoie désormais un score entre 0 et 1. Vous pouvez ainsi filtrer programmatiquement les extractions IA dont le modèle n'est pas "certain" du résultat
- Batch Cortex Search (GA) : Une nouvelle fonction table CORTEX_SEARCH_BATCH permet d'exécuter des millions de requêtes de recherche vectorielle en une seule instruction SQL, idéal pour les traitements de masse
Architecture & moteur de calcul
- Nouvelles instances Snowpark (GA) : Arrivée d'instances basées sur ARM (plus économiques), notamment l'intégration des GPU NVIDIA L40S pour le calcul massif
- Tables Dynamiques - Mode "Adaptive" (Preview) : Un nouveau mode de rafraîchissement (REFRESH_MODE = ADAPTIVE) vient s'ajouter aux modes Full et Incremental pour optimiser automatiquement les pipelines selon la nature des changements
- Tables Dynamiques - Frozen Regions : Le concept d'"Immutability Constraint" a été renommé. Vous utiliserez désormais la clause FROZEN WHERE pour verrouiller des régions historiques de votre table
Gouvernance & Sécurité
- Rapports d'accès aux données sensibles (Preview) : Deux nouveaux rapports natifs font leur apparition : le Sensitive Data Access report (qui a vu quoi) et le Sensitive Data Entitlement report (qui a le droit de voir quoi)
- Data protection policies dans Snowsight : Une nouvelle interface graphique permet de gérer et visualiser directement les politiques de protection des données sans passer par des lignes de commande
- Changez d'édition à la volée (GA) : Les administrateurs peuvent désormais modifier l'édition d'un compte (ex: passer de Standard à Enterprise) via une simple commande ALTER ACCOUNT SET EDITION
Agenda : Prochains Rendez-Vous Snowflake
- 1 - 4 Juin 2026 : Snowflake Data Cloud Summit '26 (San Francisco) : Le rendez-vous mondial majeur
- 15 Octobre 2026 : Snowflake World Tour Paris : Next Decision sera présent, venez nous rencontrer !
Vous souhaitez bénéficier d'experts, de développeurs, ou d'une formation sur Snowflake ? Rendez-vous sur la page Contact.